Click For Docs:
Overview
How-to
How-to Overview
Deploy Image Algorithm
Deploy Audio Algorithm
Deploy Video Algorithm
Deploy Text Algorithm
Deploy Json Algorithm
Decide on a Server
Use Elastic Inference
Make an iOS App
Website for Algorithm
Use Swagger
Using Algorithm Cloud
API Types
API Types Overview
Image Data Type API's
File Data Type API's
Text Data Type API's
Audio Data Type API's
Video Data Type API's
Arrays Data Type API's
JSON Data Type API's
FAQs
More Resources
Choosing Servers
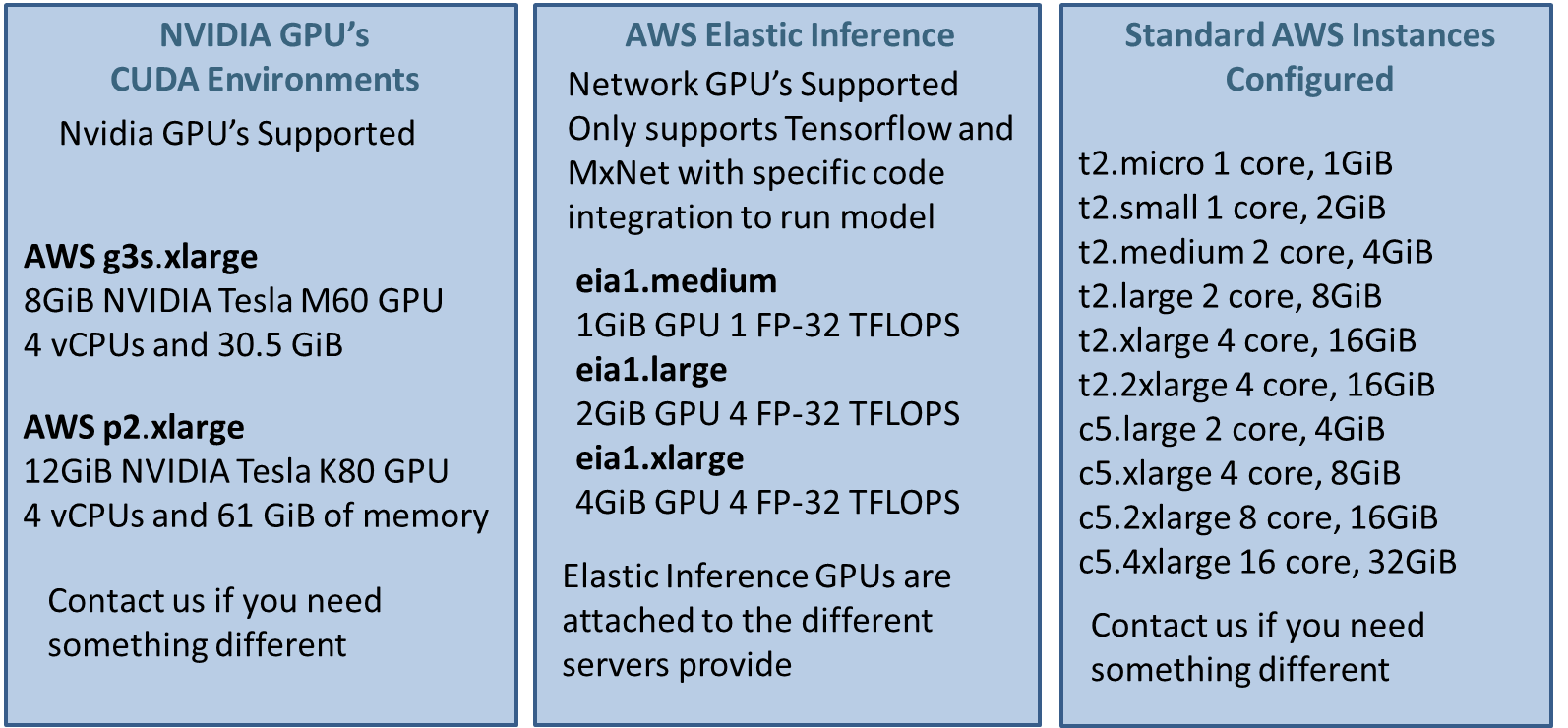
Automated.ai Algorithm Cloud supports three main types of servers:
- Two GPU servers are supported: P2 and G3s. Both perform about the same but your choice should depend on the model size being used with the GPU.
- Elastic Inferance: Add GPU acceleration to any Amazon EC2 instance for faster inference at much lower cost (up to 75% savings) compared to using a dedicated GPU machine. The downside is all that is supported is Tensorflow, and MXNet for model deployment. The GPU's described are attached to the standard servers attached for a paring of a partial GPU with the server described.
- See Amazon's website for more information on how to deploy and information: Amazon Elastic Inference
- CPU based servers with different amounts of CPU cores and Ram. Typically, choose 1 core 2GiB t2.small as it works well for most algorithms, ML and DL models where GPU acceleration is not required.
- Two types of servers are supported, t and c instances. T servers can vary in network speed and compute ability so if you require very consistent inference algorithm speed then choose C instances at a higher cost.